
(temps de lecture : 5min)
ANTwork est fier d’annoncer sa 12ème place sur 97 participants au challenge de Machine Learning organisé par l’ESA « Collision Avoidance Challenge ».

Aujourd’hui l’évitement actif de collision de satellites est une tâche routinière dans l’espace. Par exemple pour un satellite en orbite basse (LEO, Low Earth Orbit), des centaines d’alertes sont émises chaque semaine pour des cas de collisions potentielles. Après un tri automatique, il reste en moyenne deux alertes réels par satellite et par semaine à traiter. Ces cas demande un suivi détaillé par un analyste pour déterminer si en dernier ressort une manœuvre d’évitement doit être réalisée. En moyenne, pour les satellites surveillés par l’ESA, plus d’une manœuvre d’évitement est nécessaire par satellite et par an.
Les manœuvres d’évitement doivent être entreprises au plus tard deux jours avant la date prévue de la collision potentielle. Le but du challenge était, sur base d’un grand ensemble de données historiques, de construire un modèle pour prédire deux jours avant la collision potentielle le risque de collision.
Plus d’infos sur la problématique ici : https://kelvins.esa.int/media/competitions/space-collision-avoidance/SDC7-paper1017.pdf
Les détails et résultats complets du concours ici : https://kelvins.esa.int/collision-avoidance-challenge/results/
Les meilleures approches de Machine Learning à l’issue du challenge n’apportent pas de solution magique au problème. Cependant elles permettent de mettre en évidence des situations de collision dont le risque est plus bas que le niveau pour déclencher un suivi détaillé à l’avance, mais dont on peut prédire que le risque pourrait remonter fortement dans les dernières heures. Dans cette application, le Machine Learning ne permet pas de remplacer pas le suivi d’un expert mais peut lui faciliter la tâche et lui économiser quelques cheveux blancs.
Comme pour la plupart des challenges de ML, les données sont divisées en deux parties : une partie « train data » qui comprend la solution (les risques évalués à la collision) pour entraîner son modèle et une partie « test data » pour laquelle il faut évaluer la solution. Il s’agit donc d’un problème de Supervised Learning puisqu’on a la solution à disposition.
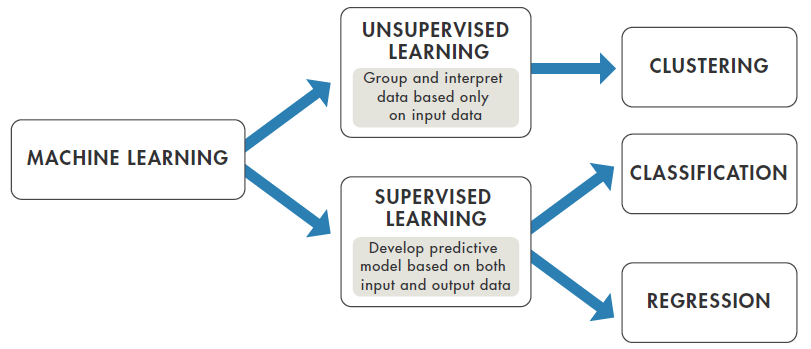
(tiré d’un e-book introductif à ML proposé par Mathworks https://www.mathworks.com/content/dam/mathworks/tag-team/Objects/i/88174_92991v00_machine_learning_section1_ebook.pdf )
Les solutions peuvent être soumises une fois par jour maximum pendant la durée du challenge pour calculer un leaderboard. Le nombre de soumissions est limité et le leaderboard n’est calculé que sur une partie du « test data » alors que le classement final est calculé sur l’ensemble des données pour éviter l’overfitting – nous y reviendrons.
Les « train data » sont composées de 162’000 messages d’alerte pour un total d’environ 13’000 collisions potentielles. Chaque message comporte 103 champs avec pour le satellite et l’objet à éviter des dizaines de paramètres comme la taille, la vitesse, les caractéristiques de l’orbite, la susceptibilité au champ magnétique, la traînée aérodynamique (oui même dans l’espace il y a du vent, extrêmement faible mais tout de même…), etc.
A première vue cela peut sembler un nombre gigantesque de données, confortable pour une solution par ML. Cependant la problématique en question demande de se focaliser principalement sur les événements à haut risque (p>10-6) ; estimer un risque à 10^-12 quand il est en réalité de 10^-9 n’est pas aussi grave que d’estimer un risque à 10^-7 s’il est en réalité de 10^-4. Pour refléter cette préoccupation, les organisateurs ont réfléchi longuement à la formule à utiliser pour le scoring et il s’agit d’une combinaison de MSE (Mean Squared Error) et de F_beta score (https://en.wikipedia.org/wiki/F1_score) avec beta=2 pour pénaliser davantage les faux négatifs que les faux positifs.
Sur le grand nombre de données disponibles, les cas de vrais positifs s’avère au final très rares: moins d’un pourcent, soit une centaine seulement. Vu le grand nombre d’informations disponibles dans chaque message d’alerte (103), le risque d’overfitting est bien présent.
Une des difficultés principales est d’extraire les informations pertinentes parmi tous les champs de données disponibles. En effet beaucoup de données sont inter-dépendantes et la plupart n’ont a priori pas d’impact sur le risque. Il est donc nécessaire de passer un certain temps à explorer les données (EDA, Exploratory data analysis) et de préférence visuellement pour sortir l’aiguille de la botte de foin. Le but est de créer des nouvelles informations plus compactes en combinant un grand nombre de données. Par exemple en faisant la différence entre le risque maximum et le risque minimum sur tous les messages d’alertes reçus pour une collision potentielle, on crée une information de la volatilité du risque qui peut être utilisée plus facilement par un algorithme de classification que si on lui rentre l’ensemble des valeurs. Cela s’appelle du feature engineering (https://en.wikipedia.org/wiki/Feature_engineering). Et c’est là que les connaissances « domaine » (ou « métier ») font la différence et permettent de tirer le meilleur profit des données par le ML. Un expert en astrodynamique pensera éventuellement à combiner le nombre de Wolf (nombre de taches solaires) avec le coefficient de radiation solaire du satellite.
Une autre difficulté vient du fait que les messages sont des séries temporelles : chaque collision potentielle contient une dizaine de messages d’alertes émis plusieurs fois par jour. Le problème consiste donc en un mélange entre un problème de classification (détecter les vrais collisions à haut risque, cas positifs) et un problème de régression (prédire le risque futur sur base des risque passées), qui sont les deux catégories de problème de supervised learning. ANTwork a développé des outils dédiés pour attaquer ce problème hybride qui ne rentre pas dans les cases prédéfinies des outils commerciaux.
La dernière difficulté est qu’en raison même du problème, le gain apporté par le Machine Learning est dans ce cas précis assez limité. Il y a donc une tentation forte à essayer des modèles de plus en plus complexes pour arriver à tirer quelque chose des données d’entraînement, mais au risque une fois encore d’overfitter les données. Il ne faut pas oublier que le Machine Learning, si on lui colle pour le grand publique l’étiquette mystérieuse d’Intelligence Artificielle, n’est en fait qu’une technique de Curve Fitting.
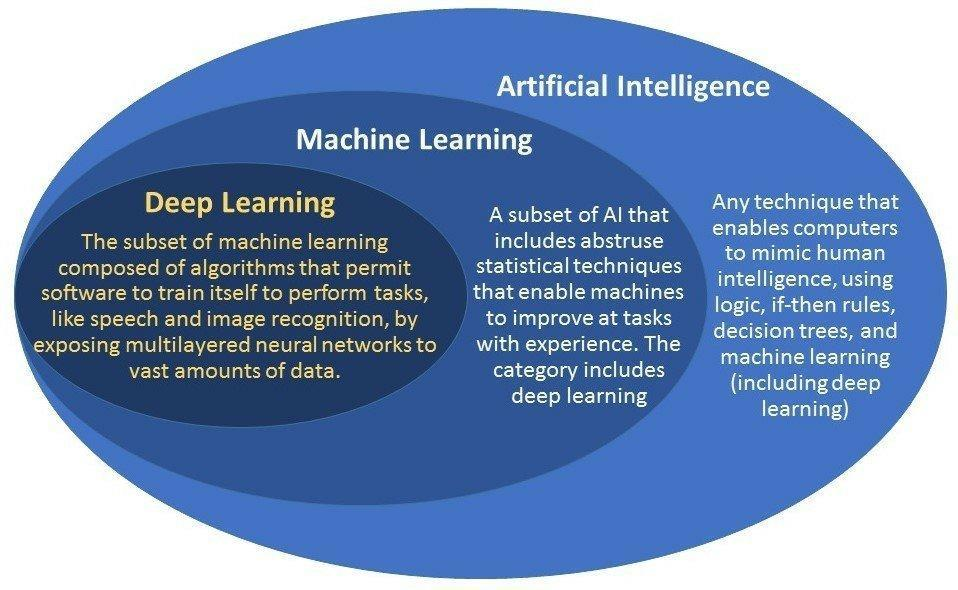
(de plusieurs sources sur google image, je n’ai pas pu trouvé l’auteur original… )
Après six semaines de nuits courtes, les résultats sont tombés.
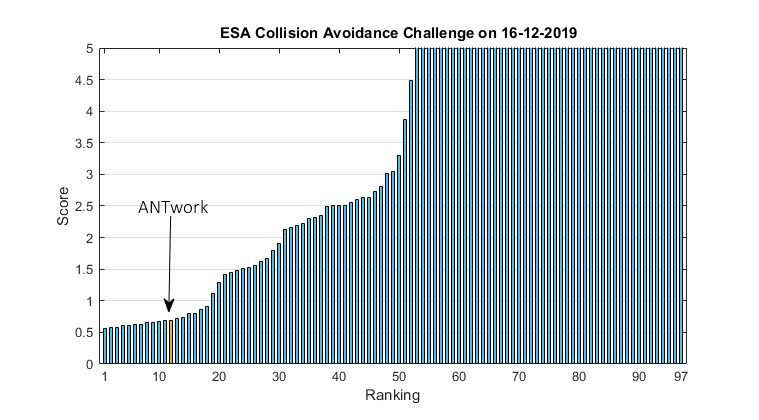
ANTwork est fier d’atteindre une douzième place sur presque cent équipes et de terminer avec un score assez proche des meilleurs.
Le bénéfice des challenges de ce type est justement de mesurer les techniques et outils employés avec l’état de l’art et d’apprendre des autres participants. Un des risques du ML réside dans la difficulté de faire un pas en arrière et de juger de la qualité de son travail. L’illusion d’une solution magique qui donne des résultats bluffants grâce à un algorithme boite noire est réelle. Une fois encore il faut retenir qu’il n’y a rien de magique dans le ML et que ce n’est que du curve fitting, rendu possible aujourd’hui par une puissance de calcul formidable à coût nul ou presque. Comme l’a prédit John von Neumann, un des plus grands mathématiciens du XXème siècle : « With four parameters I can fit an elephant, and with five I can make him wiggle his trunk »
(démonstration en 2010 par Jürgen Mayer https://aapt.scitation.org/doi/10.1119/1.3254017 )
Au final, l’équipe qui remporte le challenge détaille qu’après avoir testé un grand nombre d’algorithmes complexes (Random Forests, time-series prediction, Mutual Information, Evolutionary Optimization and GMM’s) et développé un grand nombre de nouvelles features, leur proposition gagnante consiste en une approche assez simple en quelques lignes de code.
(https://kelvins.esa.int/collision-avoidance-challenge/discussion/667/#c686)
Un autre participant sur le podium explique lui avoir entraîné 50 modèles différents et les avoir combinés avec un vote à majorité… (https://kelvins.esa.int/collision-avoidance-challenge/discussion/667/#c672) La question se pose alors de la confiance qu’un opérateur comme l’ESA pourrait avoir dans un modèle si obscure pour prendre des décisions aux conséquences peut-être dramatiques.
De son côté, ANTwork a utilisé une approche basée sur un filtre de Kalman pour générer des nouvelles features pertinentes à partir de chaque série temporelle, comme la covariance du niveau de risque. Ces features peuvent alors être utilisées dans un modèle simple de classification. Cette approche prometteuse qui permet de combiner série temporelle et classification, mériterait d’être poursuivie.
En conclusion que retenir ?
Trier et uniformiser les données avant de démarrer. Des données incomplètes ou aberrantes peuvent polluer le travail de ML.
Pour tout problème, réfléchir à l’objectif à atteindre avant de se lancer et prendre le temps d’établir une formule de score adéquate qui permettra de comparer la solution de ML avec une solution Baseline sans ML, afin d’objectiver le gain de l’approche ML
Garder une réserve de données « sous clé » (idéalement même une personne en dehors de l’équipe qui développe la solution) pour comparer les solutions sur un jeu de données qui n’a pas servi à entraîner ni valider le modèle. Il faut admettre que la tentation est grande de se dire qu’avec plus de données le modèle serait plus précis. Cela permet de déterminer de manière indépendante le vrai gain de l’approche ML. Et en cas de consensus pour l’utilisation de la solution ML en production, il est alors encore temps d’améliorer le modèle marginalement en le nourrissant de ces données conservées pour la validation finale.
Passer plus de temps à explorer les données et à faire du Feature Engineering (real job où on peut tirer profit des connaissances du domaine) qu’à jouer à l’aveugle avec les paramètres des algorithmes de ML pour gagner des dixièmes de pourcent non significatifs.
Privilégier une solution simple un peu moins performante à une solution plus compliquée avec un meilleur score final. Le risque d’overfitting sera plus faible et la robustesse et la confiance dans la solution en seront accrues. Rule of thumb : si en retirant un paramètre du modèle on perd moins d’un pourcent de précision, alors c’est un paramètre non pertinent et le modèle se portera mieux sans.